混合精度推理¶
混合精度推理是通过混合使用单精度(FP32)和半精度(FP16)来加速神经网络推理过程。相较于使用单精度(FP32)进行推理,既能能减少内存/显存占用,推理更大的网络,又能降低显存访问和计算耗时开销,在保证模型推理精度持平的情形下,提升推理效率。
一、半精度浮点类型 FP16¶
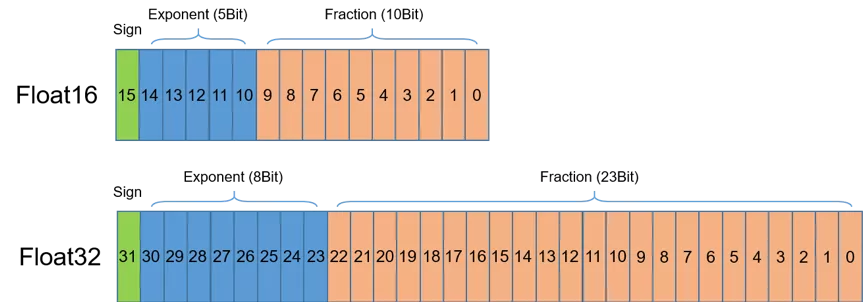
首先介绍半精度(FP16)。如图1所示,半精度(FP16)是一种相对较新的浮点类型,在计算机中使用2字节(16位)存储。在IEEE 754-2008标准中,它亦被称作binary16。与计算中常用的单精度(FP32)和双精度(FP64)类型相比,FP16更适于在精度要求不高的场景中使用。
二、NVIDIA GPU的FP16算力¶
混合精度推理使用半精度浮点(FP16)和单精度(FP32)浮点即可达到与使用纯单精度推理相同的准确率,并可加速模型的推理速度,这主要得益于英伟达从Volta架构开始推出的Tensor Core技术。在使用FP16计算时具有如下特点:
FP16可降低一半的内存带宽和存储需求,这使得在相同的硬件条件下研究人员可使用更大更复杂的模型以及更大的batch size大小。
FP16可以充分利用英伟达Volta、Turing、Ampere架构GPU提供的Tensor Cores技术。在相同的GPU硬件上,Tensor Cores的FP16计算吞吐量是FP32的8倍。
三、使用 Paddle Inference 进行混合精度推理¶
使用 Paddle Inference 提供的 API,能够开启自动混合精度推理选项,在相关 OP 的计算过程中,根据内置的优化规则,自动选择 FP32 或者 FP16 计算。
3.1 如何开启混合精度推理选项¶
3.1.1 GPU 原生推理使用混合精度¶
C++ Config 选项
Exp_EnableUseGpuFp16(std::unordered_set<std::string> gpu_fp16_disabled_op_types_)
Python Config 选项
exp_enable_use_gpu_fp16()
可以在上述 API 接口中传入 OP 名称参数列表,来排除不支持 FP16 计算的 OP 使用混合精度推理。
详细API介绍,分别参考 C++ API 文档 - Config 或者 Python API 文档 - Config
3.1.2 TensorRT 推理使用混合精度¶
为了使用TensorRT 利用半精度进行混合精度推理,需将制定精度类型参数设定为半精度。
C++ Config 选项
将以下接口中精度类型参数
precision,设定为Precision::kFloat32。void EnableTensorRtEngine(int workspace_size = 1 << 20, int max_batch_size = 1, int min_subgraph_size = 3, Precision precision = Precision::kFloat32, bool use_static = false, bool use_calib_mode = true);
Python Config 选项
将以下接口中精度类型参数
precision_mode,设定为paddle_infer.PrecisionType.Half。enable_tensorrt_engine(workspace_size: int = 1 << 20, max_batch_size: int, min_subgraph_size: int, precision_mode: PrecisionType, use_static: bool, use_calib_mode: bool)
详细API介绍,分别参考 C++ API 文档 - Config 或者 Python API 文档 - Config
3.2 混合精度推理使用示例¶
以下分别介绍 GPU 原生、TensorRT 混合精度推理示例,完整示例可参考。
3.2.1 GPU 原生混合精度推理示例¶
C++ 示例如下
paddle_infer::Config config; if (FLAGS_model_dir == "") { config.SetModel(FLAGS_model_file, FLAGS_params_file); // Load combined model } else { config.SetModel(FLAGS_model_dir); // Load no-combined model } config.EnableUseGpu(1000, 0); config.Exp_EnableUseGpuFp16(); config.SwitchIrOptim(true); auto predictor = paddle_infer::CreatePredictor(config);
Python 示例如下
if args.model_dir == "": config = Config(args.model_file, args.params_file) else: config = Config(args.model_dir) config.enable_use_gpu(1000, 0) config.exp_enable_use_gpu_fp16() config.switch_ir_optim(True) predictor = create_predictor(config)
3.2.2 TensorRT 混合精度推理示例¶
C++ 示例如下
paddle_infer::Config config;
if (FLAGS_model_dir == "") {
config.SetModel(FLAGS_model_file, FLAGS_params_file); // Load combined model
} else {
config.SetModel(FLAGS_model_dir); // Load no-combined model
}
config.EnableUseGpu(1000, 0);
config.EnableTensorRtEngine(1 << 30, FLAGS_batch_size, 5,
PrecisionType::kHalf, false, false);
config.SwitchIrOptim(true);
auto predictor = paddle_infer::CreatePredictor(config);
Python 示例如下
if args.model_dir == "":
config = Config(args.model_file, args.params_file)
else:
config = Config(args.model_dir)
config.enable_use_gpu(1000, 0)
config.enable_tensorrt_engine(
workspace_size = 1<<30,
max_batch_size=1, min_subgraph_size=5,
precision_mode=paddle_infer.PrecisionType.Half,
use_static=False, use_calib_mode=False)
config.switch_ir_optim(True)
predictor = create_predictor(config)
四、混合精度推理性能优化¶
Paddle Inference 混合精度推理性能的根本原因是:利用 Tensor Core 来加速 FP16 下的matmul和conv运算,为了获得最佳的加速效果,Tensor Core 对矩阵乘和卷积运算有一定的使用约束,约束如下:
4.1 矩阵乘使用建议¶
通用矩阵乘 (GEMM) 定义为:C = A * B + C,其中:
A 维度为:M x K
B 维度为:K x N
C 维度为:M x N
矩阵乘使用建议如下:
根据Tensor Core使用建议,当矩阵维数 M、N、K 是8(A100架构GPU为16)的倍数时(FP16数据下),性能最优。
4.2 卷积计算使用建议¶
卷积计算定义为:NKPQ = NCHW * KCRS,其中:
N 代表:batch size
K 代表:输出数据的通道数
P 代表:输出数据的高度
Q 代表:输出数据的宽度
C 代表:输入数据的通道数
H 代表:输入数据的高度
W 代表:输入数据的宽度
R 代表:滤波器的高度
S 代表:滤波器的宽度
卷积计算使用建议如下:
输入/输出数据的通道数(C/K)可以被8整除(FP16),(cudnn7.6.3及以上的版本,如果不是8的倍数将会被自动填充)
对于网络第一层,通道数设置为4可以获得最佳的运算性能(NVIDIA为网络的第一层卷积提供了特殊实现,使用4通道性能更优)
设置内存中的张量布局为NHWC格式(如果输入NCHW格式,Tesor Core会自动转换为NHWC,当输入输出数值较大的时候,这种转置的开销往往更大)