推理流程¶
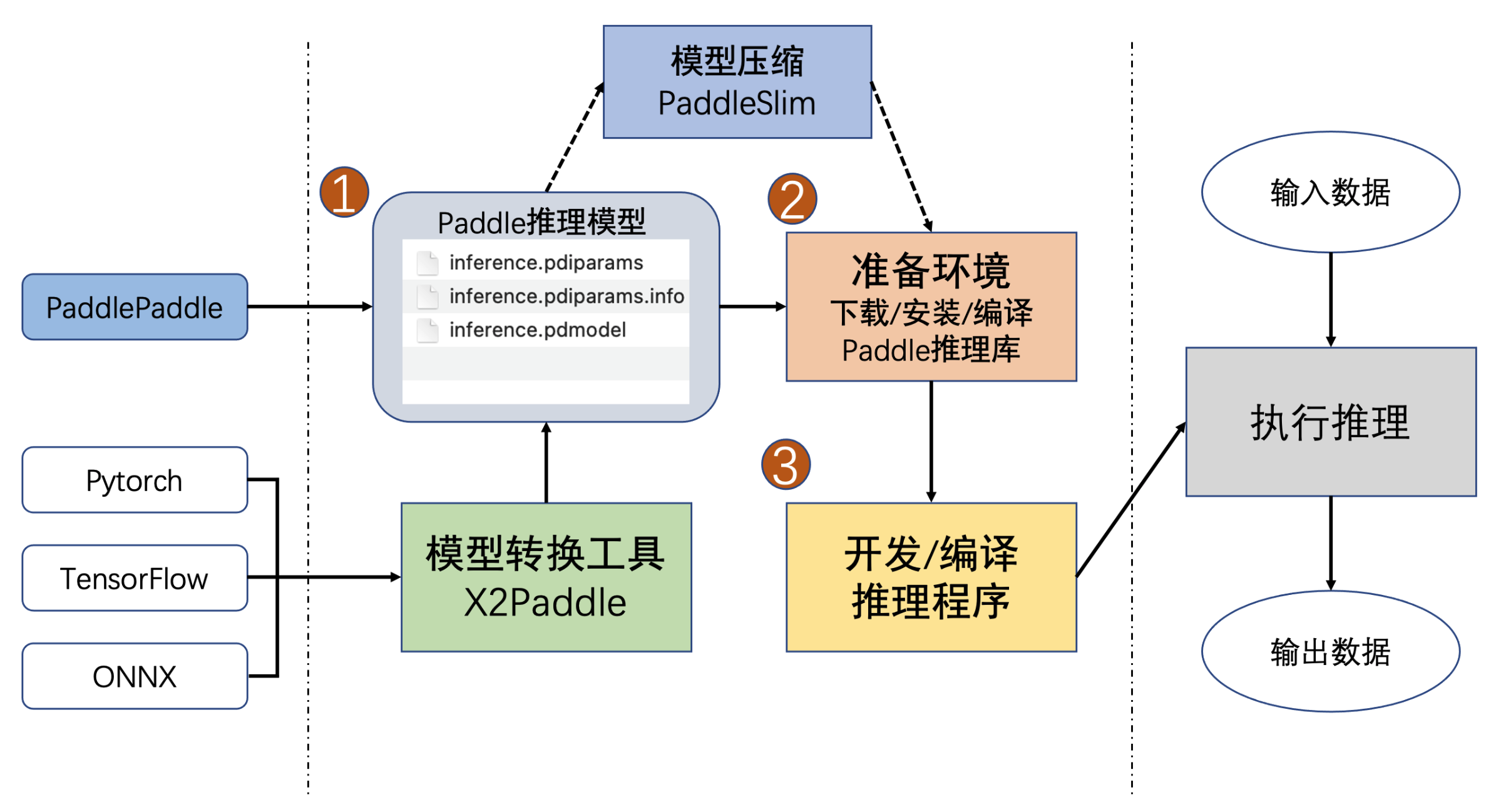
一. 准备模型¶
Paddle Inference 原生支持由 PaddlePaddle 深度学习框架训练产出的推理模型。PaddlePaddle 用于推理的模型分别可通过 paddle.jit.save (动态图) 与 paddle.static.save_inference_model (静态图) 或 paddle.Model().save (高层API) 保存下来。如果您手中的模型是由诸如 TensorFlow、PyTorch 等框架产出的,那么您可以使用 X2Paddle 工具将模型转换为 PadddlePaddle 格式。
更详细的模型导出说明请参考模型导出文档。
可以使用模型可视化工具来查看您的模型结构,以确认符合组网预期。
二. 准备环境¶
可参照 Paddle Inference 安装 页面,通过下载预编译库或源码编译的方式准备 Paddle Inference 的基础开发环境。
三. 开发推理程序¶
Paddle Inference 采用 Predictor 进行推理。Predictor 是一个高性能推理引擎,该引擎通过对计算图的分析,完成对计算图的一系列的优化(如 OP 的融合、内存 / 显存的优化、 MKLDNN,TensorRT 等底层加速库的支持等),能够大大提升推理性能。
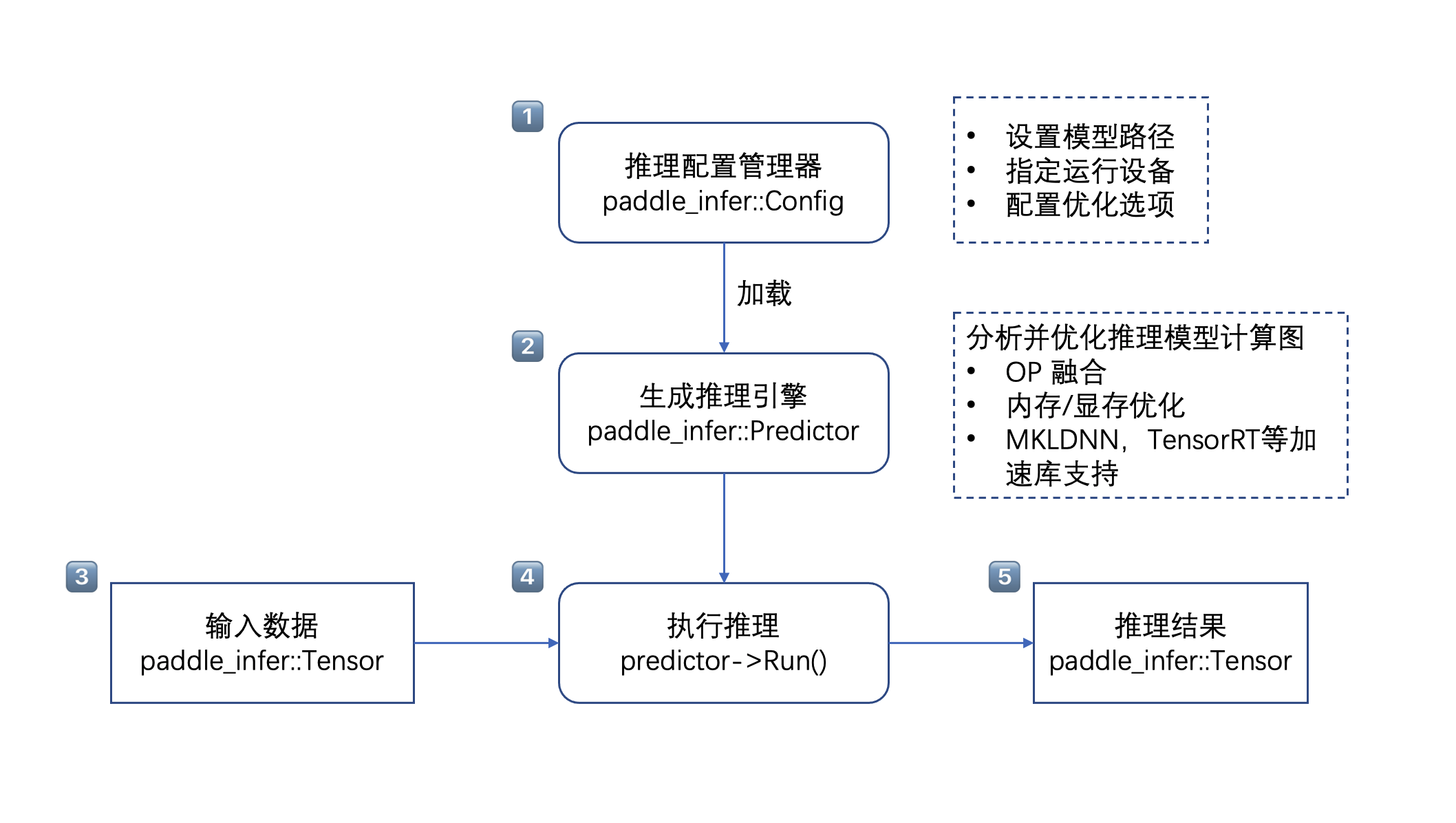
开发推理程序只需要简单的 5 个步骤 (这里以 C++ API 为例):
配置推理选项
paddle_infer::Config,包括设置模型路径、运行设备、开启/关闭计算图优化、使用 MKLDNN / TensorRT 进行部署的加速等。创建推理引擎
paddle_infer::Predictor,通过调用CreatePredictor(Config)接口,一行代码即可完成引擎初始化,其中Config为第1步中生成的配置推理选项。准备输入数据,需要以下几个步骤
将原始输入数据根据模型需要做相应的预处理,比如减均值等标准化操作
先通过
auto input_names = predictor->GetInputNames()获取模型所有输入 Tensor 的名称再通过
auto tensor = predictor->GetInputTensor(input_names[i])获取输入 Tensor 的指针最后通过
tensor->copy_from_cpu(data),将预处理之后的数据 data 拷贝到 tensor 中
执行推理,只需要运行
predictor->Run()一行代码,即可完成推理执行获得推理结果并进行后处理,需要以下几个步骤
先通过
auto out_names = predictor->GetOutputNames()获取模型所有输出 Tensor 的名称再通过
auto tensor = predictor->GetOutputTensor(out_names[i])获取输出 Tensor的 指针最后通过
tensor->copy_to_cpu(data),将 tensor 中的数据 copy 到 data 指针上可以使用与训练完全相同的输入数据进行推理并对比结果一致性,或者批量推理验证数据集并计算模型精度的方式来判断推理结果的正确性
将模型推理输出数据进行后处理,比如根据检测框位置裁剪图像等
Paddle Inference 提供了 C, C++, Python, Golang 四种 API 的使用示例和开发说明文档,您可以参考示例中的说明快速了解使用方法,并集成到您自己的项目中去。
四. 性能优化¶
1) 根据实际场景开启相应的推理优化配置项¶
以 C++ API 为例,根据实际场景开启相关的优化开关,示例如下,具体请参考 C++ API 文档。
CPU 推理:
EnableMKLDNN、EnableMkldnnBfloat16、SetCpuMathLibraryNumThreads、EnableONNXRuntime等GPU 推理:
EnableTensorRtEngine等基础优化:
SwitchIrOptim、EnableMemoryOptim等
参考系统调优概述使用混合精度推理和多线程推理。
2) 使用 PaddleSlim 进行模型小型化¶
如果开启以上相关优化配置后,还需要进一步提升推理性能,可以在我们提供的深度学习模型压缩工具库 PaddleSlim 的帮助下,通过低比特量化、知识蒸馏、稀疏化和模型结构搜索等方式,进行模型小型化。